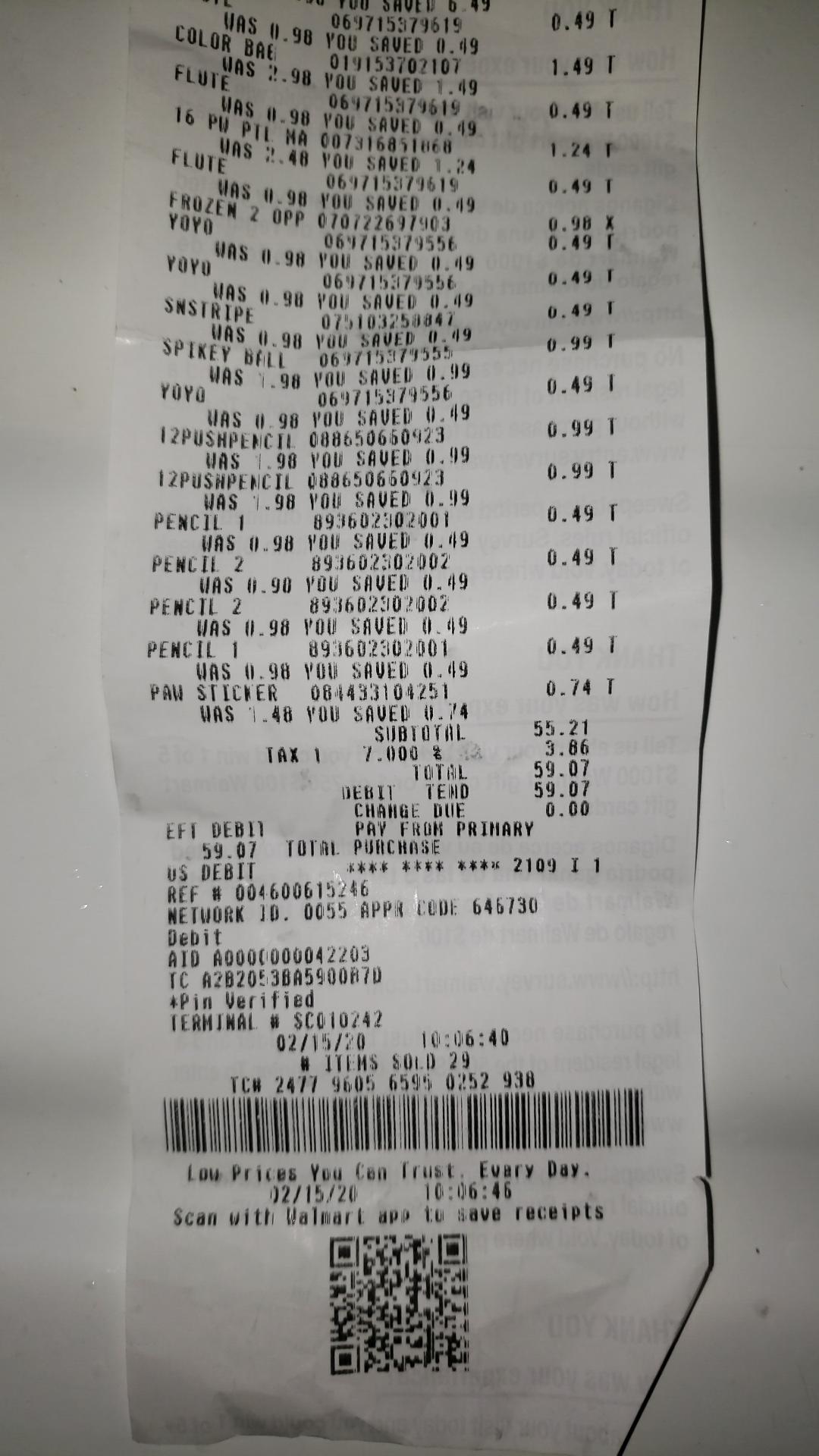
From what I can tell (without having read the research papers) it looks like this is just an easy to use package for sparse scene text extraction. It seems to do okay if the scene has sparse text but it falls down for dense text detection. The results are going to be pretty bad if you try and do a task like "extract transactions from a picture of a receipt." Here's an example of input you might get for a production app: https://www.clusin.com/walmart-receipt.jpg
{kind=link}
Notice the faded text from the printer running out of ink and the slanted text. From limited experience each of these are thorny problems and the state of the art CV algorithms won't help you escape from having to learn how to algorithmicly pre-process images and clean them up prior to feeding them into a CV algorithm. You might be able to use Google's Cloud OCR but that charges per image, although it is pretty good. Even if you use that you've graduated to the next super difficult problem which is Natural Language Processing.
Once you have the text you need to determine if it has meaning to your application. That's basically what NLP is about. For the receipts example, how do you know you're looking at a receipt? What if its a receipt on top of a pile of other receipts? How do you extract transactions from the receipt? Does a transaction span multiple lines? How can you tell? etc etc etc.
I'm just happy to see some advancement in open source OCR for Python. Last time I had a Python project that needed OCR, I found that the open-source options were surprisingly limited, and it required some effort to achieve consistently good results even with relatively clean inputs.
Honestly I was kind of surprised that good basic OCR isn't a totally solved issue with an ecosystem of fully open-source solutions by now.
> Honestly I was kind of surprised that good basic OCR isn't a totally solved issue with an ecosystem of fully open-source solutions by now.
Yes! Can anyone comment on why this is the case, since OCR is proclaimed to be a solved problem?
I've always wondered why Google Lens works "out of the box" and shows great accuracy on extracting text from images taken using a phone camera, but open-source OCR software (Tesseract, Ocropy etc.) needs a lot of tweaking to extract text from standard documents with standard fonts, even after heavily pre-processing the images.
PS: Has Google released any paper on Google Lens?
We were basically trying to transcribe message screenshots which should have been relatively straightforward given the homogeneity of the font. But this was not the case as tesseract was not trained in the layout of msg screenshots. The accuracy of raw tesseract on our test dataset was somehwere about 0.5-0.6 BLEU.
Once we were able to isolate individual parts of the image and feed it to tesseract, we were able to get around 0.9 BLEU on the same dataset.
TLDR;Some nifty image processing is required to make tesseract perform as expected.
[0] (https://www.askgoose.com) [1] (https://github.com/tesseract-ocr/tesseract)